Danny Malter
VP Data Science and Machine Learning - Intellicheck
M.S. in Predictive Analytics - DePaul University

Me
Malter Analytics
GitHub
LinkedIn
YouTube Channel
Kaggle
Other Work
Into to Python Course
General Assembly
AriBall
Media
Built In
Guide to Runnng RHadoop over Amazon EMR
Assumptions
That you have already set up an Amazon AWS account.
That you have basic knowledge of the following:
- Amazon EMR (Elastic MapReduce)
- Amazon S3 (Simple Storage)
- Amazon EC2 (Elastic Compute Cloud)
- R Programming
Setting up Elastic Map Reduce
Step 1: Log into Amazon AWS
Step 2: Click the EMR icon - Managed Hadoop Framework
Step 3: Create your cluster
- Click “Create cluster” and select “Go to advanced options” at the top of the page
- Give your cluster a name
- Log folder S3 location: Select any location in S3 for logs
- Software configuration: This demo is done using Amazon Hadoop 2 version 3.10.0
- Add any applications you are interested in using, such as Spark or Mahout
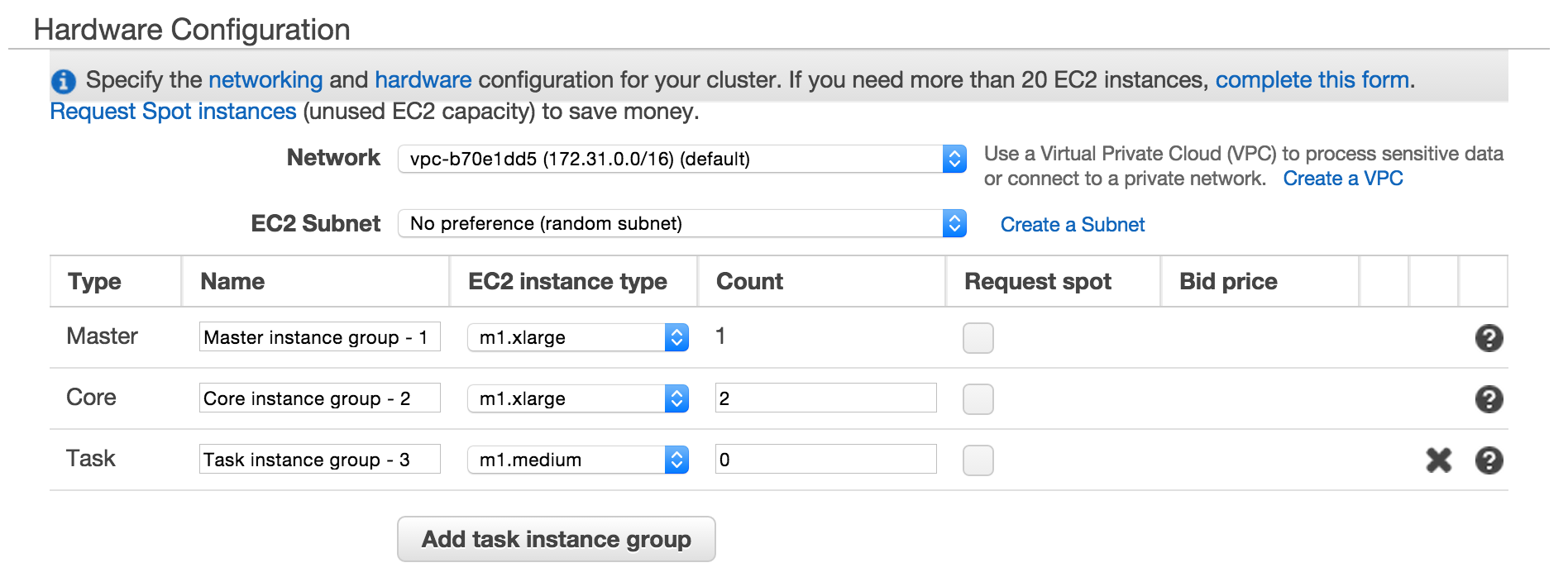
- Choose an EC2 instance: This demo is done using m1.xlarge (Master & Core) and m1.medium (Task)
- Choose your EC2 key pair
IMPORTANT BOOTSTRAP INSTRUCTION
- Download the Amazon EMR Boostrap File
- Open a new tab and upload the .sh script into your S3 (either create a new folder/bucket in S3 or use an existing folder)
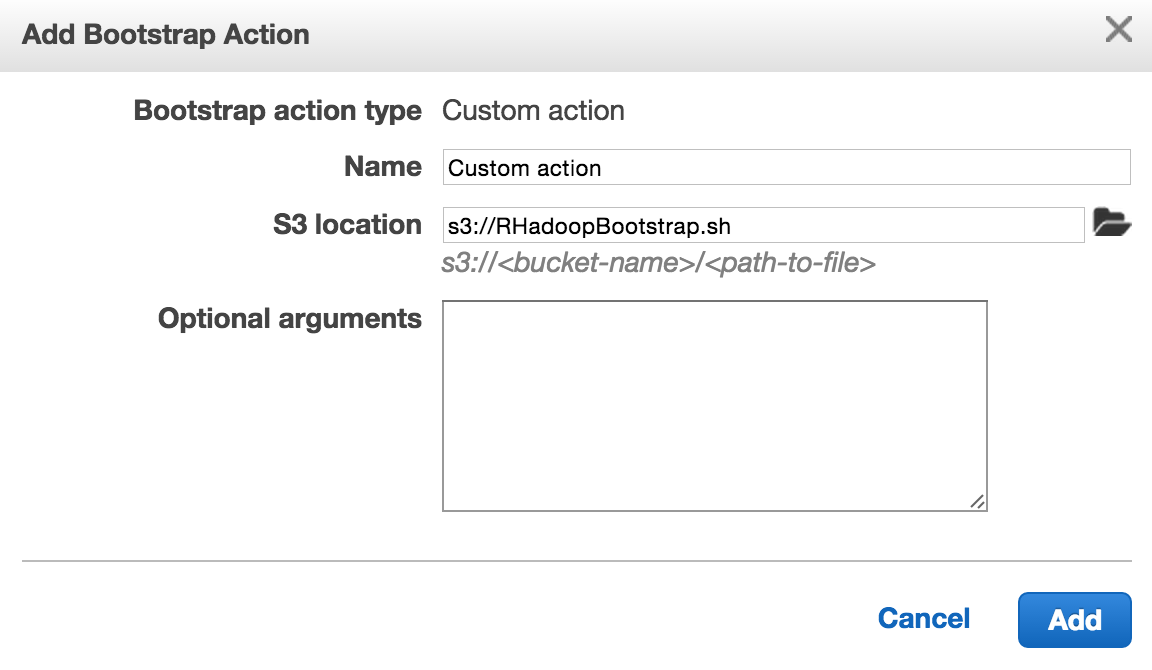
- Within EMR, select “custom action” from the “Select a boostrap action” drop down. Then select “Configure and add”
- Link the above .sh file in “S3 location” and press “Add”
- Select any other fields as you wish and click on the “Create cluster” button
IMPORTANT NOTE:
The cluster will initially show as “pending”. With the bootstrap script, the cluster will take around 15 to fully complete the setup process.
Initial Stage:
- All steps should be “Pending”
Second Stage:
- Progress should be shown as “Bootstrapping”
Final Stage:
- Cluster will be shown as “Running”
- Your EMR cluster is now ready to be used with RHadoop.
Running R over the Cluster
Open the Terminal and connect to your cluster with the following code
ssh -i /path/to/keypair.pem hadoop@Amazon_Public_DNS
Once connected, either make a directory for your input file or download directly into the /home/hadoop directory. You can imort data from Amazon S3 with the wget command. The file link can be found under ‘Properties’ within S3 and you will need to make sure that the correct permissions are set for the file to be downloaded.
# Create a local directory with the data
mkdir data
cd data
wget https://s3-us-west-2.amazonaws.com/bucket-name/shakespeare.txt
# Another option by downloading the file from a url
shakespeare_works <- "data/shakespeare_works.txt"
if(!file.exists(shakespeare_works)) {
download.file(url = "http://www.gutenberg.org/ebooks/100.txt.utf-8",
destfile = shakespeare_works)
}
Word Count Example
The following code is an example of running a word count on a text file using the rmr2 package and loading data into HDFS with the rhdfs package.
sudo R
Sys.setenv(HADOOP_HOME="/home/hadoop");
Sys.setenv(HADOOP_CMD="/home/hadoop/bin/hadoop");
Sys.setenv(JAVA_HOME="/usr/lib/jvm/java") ;
Sys.setenv(HADOOP_PREFIX="/home/hadoop/");
Sys.setenv(HADOOP_STREAMING="/home/hadoop/contrib/streaming/hadoop-streaming.jar");
library(rmr2)
library(rhdfs)
hdfs.init()
# Copy the file to HDFS
hdfs.mkdir("/user/shakespeare/wordcount/data")
hdfs.put("/home/hadoop/data/shakespeare.txt", "/user/shakespeare/wordcount/data")
map = function(.,lines)
{ keyval(
tolower(
unlist(
strsplit(
x = lines,
split = " +"))),
1)}
# Splits text by at least one space
reduce = function(word, counts) {
keyval(word, sum(counts))
}
wordcount = function (input, output=NULL) {
mapreduce(input=input, output=output, input.format="text",
map=map, reduce=reduce)
}
hdfs.root <- '/user/shakespeare/wordcount'
hdfs.data <- file.path(hdfs.root, 'data')
hdfs.out <- file.path(hdfs.root, 'out') # 'out' must not be an already created folder
system.time(out <- wordcount(hdfs.data, hdfs.out))
results = from.dfs(out)
results.df = as.data.frame(results, stringsAsFactors=FALSE)
install.packages('tm')
library(tm)
sw <- stopwords()
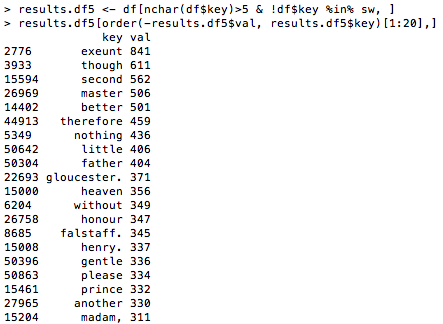
top.words5 <- results.df[nchar(results.df$key)>5 & !results.df$key %in% sw, ]
top.words5[order(-top.words5$val, top.words$key)[1:20], ]
Example of output:
Aggregation Example
hdfs.mkdir("/user/purchases/data")
hdfs.put("/home/hadoop/data/purchases.txt", "/user/purchases/data")
purchases.map <- function(k, v){
city <- v[[3]]
dollars <- v[[5]]
return( keyval(city, dollars) )
}
purchases.reduce = function(k, v) {
keyval(k, sum(v))
}
purchases.format <- make.input.format("csv", sep = "\t")
m = function (input, output=NULL) {
mapreduce(input='/user/purchases/data', output='/user/purchases/out18', input.format=purchases.format,
map=purchases.map), reduce=purchases.reduce)
}
hdfs.root <- '/user/purchases/'
hdfs.data <- file.path(hdfs.root, 'data')
hdfs.out <- file.path(hdfs.root, 'out')
system.time(out <- m(hdfs.data, hdfs.out))
results = from.dfs(m)
results.df = data.frame(results$key, results$val)
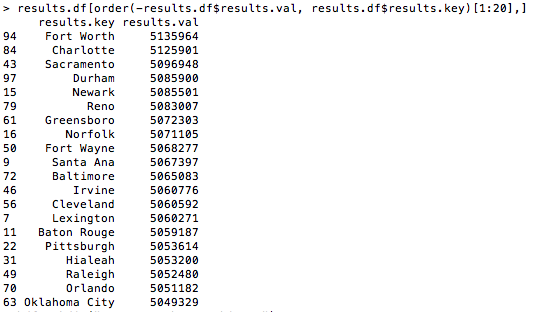
results.df[order(-results.df$results.val, results.df$results.key)[1:20],]
Example of output:
REMEMBER TO STOP OR TERMINATE YOUR INSTANCE